
Introduction
`Kubectl` is a powerful tool for Kubernetes cluster management, but at the same time, it could be complicated when you are responsible for multiple clusters or users, which is quite common in daily DevOps operations. The topic today, Kubernetes Context, is what you need to know.
Kubernetes Context includes all the information required to connect to a Kubernetes cluster, like cluster hostname, port, and authentication method. It is stored in a YAML file known as `Kubeconfig`. As previously stated, a single `Kubeconfig` file can accommodate multiple contexts. You can separate into multiple files if you would like to keep things clear.
Understand the Structure
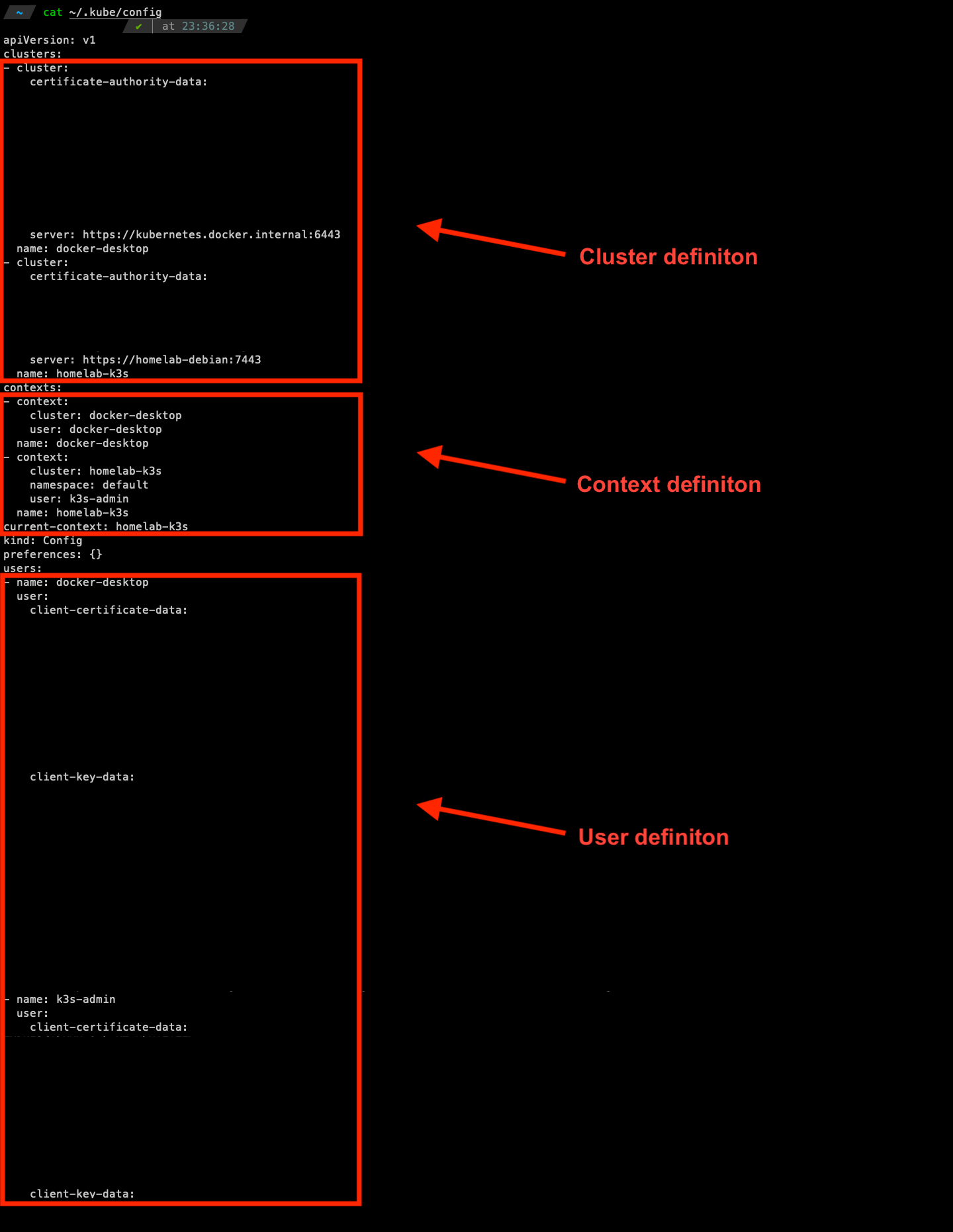
We can take the `Kubeconfig` apart to understand what a Context is. In a `Kubeconfig` file, there are three main sections, which are `clusters`, `contexts`, and `users`. They all are an array of objects to fulfil the needs of multiple clusters, contexts, and users.
The default location of the `Kubeconfig` file is `~/.kube/config`.
Example of a `Kubeconfig` file:
In the above example, it includes the information of a cluster and a user. The context `k3s-admin` has been defined to use the user `admin` of cluster `k3s` and specified `default` as the namespace.
Clusters
The `clusters` object defines the endpoint of the cluster API server and the client certificate for the SSL handshake. You can provide either the path of the certificate file or the base64 encoded certificate data. There is also a Boolean flag that allows you to skip verifying the server’s certificate.
Example of defining 3 clusters:
In the above example, there are three clusters with different ways to handle the SSL handshake. For the `insecure-skip-tls-verify` field, it is highly not recommended in any production environment. It can be used on clusters for development or testing purposes.
Users
The `users` object defines the client credentials for authenticating to a cluster. You can choose from `client-certificate`, `client-key`, `token`, ‘exec’, and ’auth-provider’ as the credential. In the `Kubeconfig`, you will need to provide a name for each set of credentials.
You should choose the best authentication method for your clusters as it is used for connections to all environments including production. The best practice is always not to store any sensitive information in your `Kubeconfig` file.
The list below explains the differences among the authentication methods.
- Token: After basic authentication had been deprecated since v1.19, it could be the worst authentication method from a security perspective. While using this method, you provide a token to access the cluster. It has a similar risk to basic authentication as you store the token in the `Kubeconfig` file. If your `Kubeconfig` file gets leaked, your cluster could be compromised. Therefore, it is not suggested to be used on production cluster authentication.
- Client-certificate/Client-key: This method is to authenticate by using a client certificate and key file. Same as the certificate field in the `clusters` section, you can provide either the path of files or the Base64-encoded data. It could be a bit safer compared to using tokens as the certificate and key are separated into two files. However, it is still not suggested to be used on production cluster authentication.
- Exec/Auth-provider: `exec` and `auth-provider` are the most recommended among all supported methods by major cloud providers, as it doesn’t require any sensitive information stored in the `Kubeconfig` file. It is a way that the authentication is performed by managed CLI tools, like `aws`, `az`, and `gcloud`. It uses the information provided in the `Kubeconfig` file to fetch the authentication tokens.
Examples of each authentication method:
Contexts
After we have defined `clusters` and `users`, `contexts` is used to link them together as different connection profiles. While using any `kubectl` command, you execute them on a context, which is a combination of cluster, user, and namespace configuration.
Under this format, you can have multiple contexts for several patterns. For instance,
- Context 1: Cluster `dev-cluster`, User `token-user`, Namespace `default`
- Context 2: Cluster `dev-cluster ` and User `cert-user`, Namespace `application`
- Context 3: Cluster `qa-cluster` and User `exec-user`, Namespace ‘application`
- Context 4: Cluster `prod-cluster` and User `auth-provider-user`, Namespace `kube-system`
It benefits cluster operations when you have multiple roles in the same or different clusters.
Example of multiple contexts:
You can also specify the current context in the `Kubeconfig` file.
Using `kubectl` with contexts
Once you have configured your contexts, you can communicate to the cluster API server using `kubectl`. In this section, you will see how to utilize the power of contexts while using `kubectl`.
kubectl config view
This command prints the `Kubeconfig` file so that you can quickly verify if the information has been set correctly.

kubectl config get-contexts
This command lists all the contexts available under your current `Kubeconfig `file.

You can easily know the list of contexts with the cluster name, username, and the default namespace. It is helpful when you have a long list of contexts to prevent confusion.
As this command reflects the content of your `Kubeconfig` file, you can see a matching content between the command output and the `Kubeconfig` file.
kubectl config current-context
This command shows the current context your `kubectl` is running on. While having multiple contexts, it is important to know the current context configured before executing any commands.

The output of this command returns the `current-context` field in your `Kubeconfig` file.

kubectl config use-context <context name>
This command updates the current context your `kubectl` is running on. You can switch between contexts easily.

kubectl config set-context <context name> <actions>
This command allows you to update a specific context without touching the `Kubeconfig` file directly.

From the figure, you can see the namespace field has changed from `default` to `kube-system` after executing the `set-context` command.
kubectl get <resources> --context <context name>
This command can get the resource information immediately by specifying the context name in the command. It is helpful when you would like to retrieve information quickly without switching between contexts.

From the above figure, it returns the Pods information of context `docker-desktop` even if it is not the current context by specifying the context in the `get` command. Without the specification, it returns the information of `homelab-k3s`.
This command is one of the examples. You can add the `--context` to many other `kubectl` commands. Check the examples below.

Best Practices to Use Context
To better utilize Kubernetes Context, I have prepared some best practices.
- Use a simple and easy name for your contexts.
Every time while switch between contexts, you are mostly reading the name to choose the context you want, then switch by providing the name. Therefore, a descriptive name would help you from being confused on working with multiple clusters and users, as using the wrong cluster could lead to a serious issue. - Secure your `Kubeconfig` file.
As previously mentioned, there are several ways of cluster authentication. Some of them like `token` and `client-certificate/client-key` are storing the credentials directly into the file. As a result, the leak of the `Kubeconfig` file could lead to a high level of security issues. Keep your file safe and only use more secure authentication methods in the production environments. - Run context switching regularly.
It is important to ensure commands and operations are executed in the intended cluster. You should regularly switch between contexts using the `kubectl config use-context <context name>` command.
- Automate context management. | To minimize human error during setting up a new context or updating an existing context, it is suggested to streamline the processes using scripts or tools. One possible automation could be making good use of `kubectl config set-context` or `kubectl config set-credentials`.
- Regular validation | Periodically reviewing your context configurations would only bring benefits to you. It is common to have outdated or unused contexts and you should remove them to reduce clutter. Maintaining a healthy `Kubeconfig` file will also decrease the chances of making mistakes.