
Kubernetes Operators are often used to automate a piece of infrastructure and allow for granular control on how deployments are observed, how pods are deployed, and provide an overall better way of controlling what’s being done within a Kubernetes Cluster.
The official documentation from Kubernetes is fairly short and vague. It doesn’t provide a deep dive into the operator pattern, the advantages of building your infrastructure this way, and doesn’t discuss some of the challenges or times where you might want to avoid using operators.
Our goal with this tutorial is to provide you with the fundamentals of Kubernetes operators, discuss how to design them, how to automate deployments and ultimately provide you with the knowledge to utilise them in your projects.
Understanding Kubernetes Deployments, Kubernetes Operators, and Control Loops
Before we introduce the concept of Kubernetes Operators, we must get to the same level of understanding of Kubernetes Deployments and the control loop responsible for monitoring the current state of the cluster.
The schema for a Deployment is detailed in the Kubernetes API under the 'apps/v1' group. To explore the complete specification, refer to the Kubernetes reference documents. This specification outlines the Deployment kind, including a comprehensive list of its fields, along with their descriptions and data types. The deployment file is specified a markup language called YAML. Within this specification, you’ll find the applications that will run within the cluster, the number of replicas (or number of “clones”), the ports that will be used for internal / external traffic routing, the versions of these applications, and more. In short, the deployment file is what specifies what will live within the cluster and the behaviors of those components. It’s important to note that it’s possible to have multiple YAML files that specify disjointed deployments within the same cluster.
Here’s a basic example of a deployment file:
There are many ways in which Kubernetes can be deployed. If you’re using a local environment, you’re likely to have an installation via Docker Desktop or minikube. In either case, you can issue the following command to send a request to the K8S API Server to deploy your application by following the instructions within your YAML file.
What happens after the command above is issued?
Well, the first step the K8S API Server will go through is validating the file - it will parse the configuration you’ve created, make sure the syntax is correct, and ensure that it’s compliant with the Kubernetes specifications the details of which can be found in the documentation.
Once a deployment file has been validated, the API Server will add a new Deployment object into the cluster via the Kubernetes control application - etcd. It’s important to note that at this point, no nodes, or pods are created.
The control plane, will run a periodic check of what’s currently in the cluster, confirm the settings within the deployments, and initiate action if what’s specified doesn’t match the current inventory. In other words, every cycle, Kubernetes will verify what the user expects to be running versus what’s actually running as specified by the Deployment files; if the two don’t match, Kubernetes will start spinning up assets that are missing.
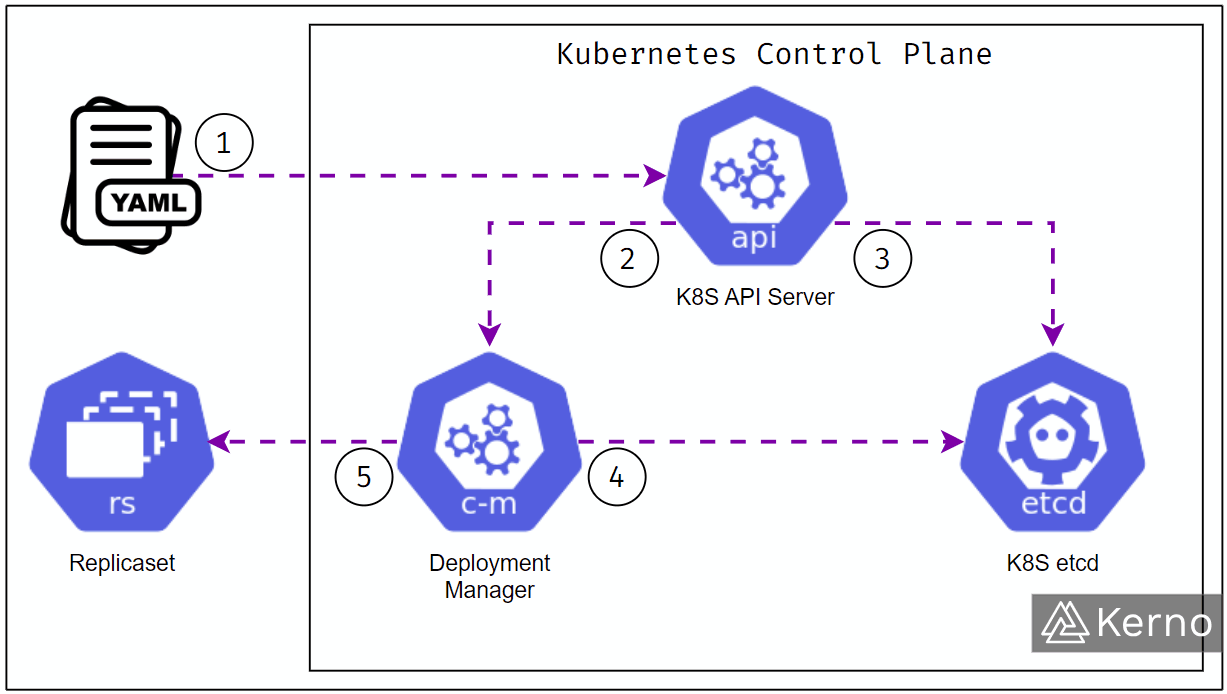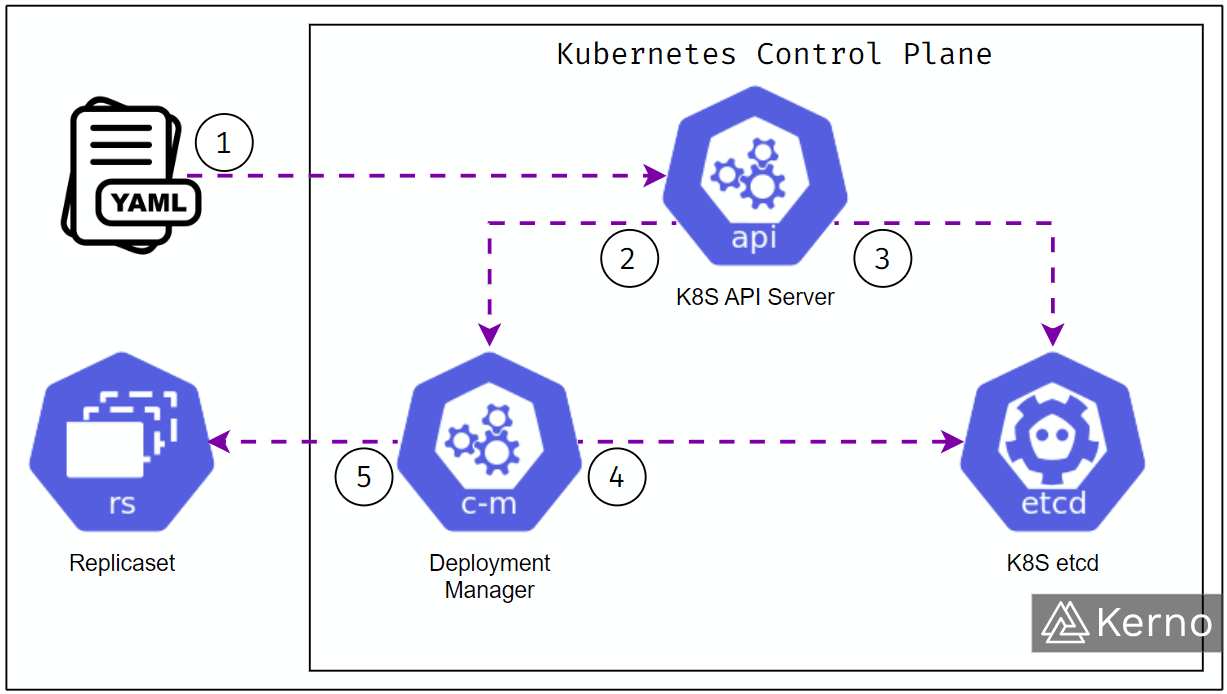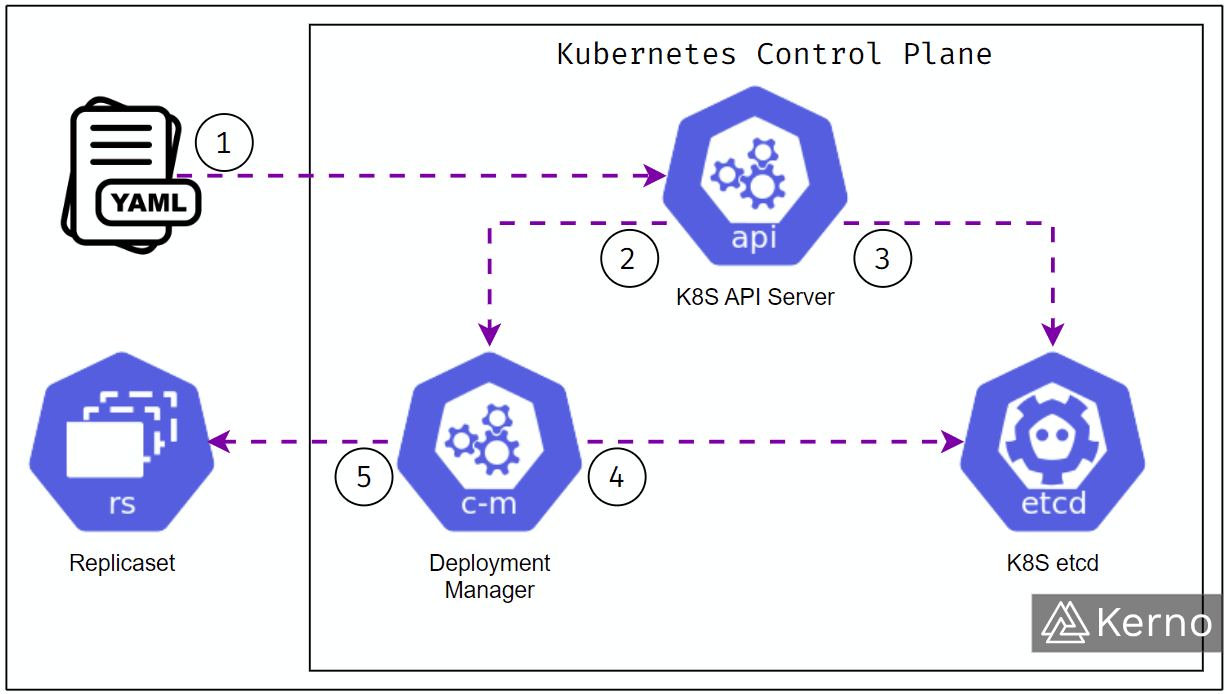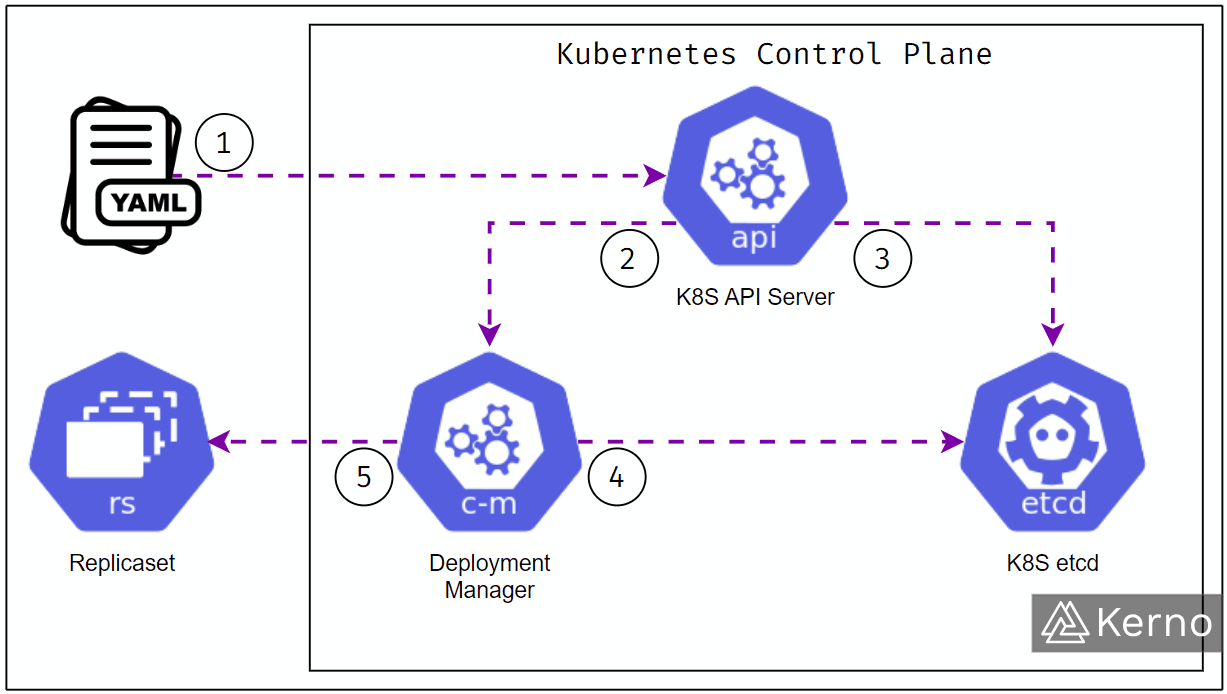
The image above is a simplified representation of what happens under the hood when a new Deployment is made in Kubernetes. Here are the steps based on the diagram:
- Deployment of the YAML file to the K8S API Server.
- The API Server notifies the Deployment controller of the new Deployment within the cluster.
- The API Server writes the Deployment to etcd.
- The Deployment manager parses the specification of every Deployment within etcd and validates against the current assets within the cluster.
- The Deployment manager creates new assets - replicas, pods, nodes, etc.
Note that we’ve oversimplified what actually happens. The control loop of Kubernetes runs at all times and needs to read the state of a variety of assets before confirming with the Deployment manager and etcd.
Kubernetes Operators | Understanding the Pattern
As we briefly mentioned above, the documentation for operators within the Kubernetes ecosystem is fairly ambiguous. Although they’re described as a single component, operators are comprised of multiple elements.
Fundamentally, operators will fit into the Kubernetes infrastructure by making the control loop process “better.” In other words, if you understood what happens when a Deployment is made, you can think of operators as software defined elements that can customize the process of how Deployments are spun up, which ressources, and in what priority are created within the cluster, etc. In simple terms, Kubernetes operators allow for a software defined granular process for Deployments.
There are two main components of an Operator - Custom Resource Definition and Custom Resources.
Kubernetes Operator | Custom Resource Definition [CDR]
A Custom Resource Definition, or CDR in Kubernetes Operators enables the creation of custom resources that are managed just like built-in Kubernetes objects. CRDs serve as the schema for custom resources which the Operator can manage. By defining a CRD, developers can define a new resource type with its own unique API endpoints, allowing for custom behaviors and automation within K8s. This extension mechanism is crucial for creating domain-specific controllers that monitor, adjust, or otherwise interact with these custom resources, enabling seamless integration and management of complex applications and services within Kubernetes.
Kubernetes Operator | Custom Resource [CR]
Custom Resources, or CRs are user-defined resource types, distinct from the built-in types like Pods or Services, and are designed to work within the Operator's domain of expertise. They serve as the primary interface for managing the lifecycle of application instances and encapsulating the desired state of these instances. When a CR is deployed, it triggers the Operator's control logic, typically implemented in a custom controller, which interprets the CR's specifications and takes necessary actions to achieve or maintain the defined state. This mechanism allows for sophisticated, application-aware operations within Kubernetes, making CRs pivotal for complex application management and orchestration.
The Kubernetes Control Loop & Deployments
Now that we have a foundational understanding of Kubernetes Operators, let’s go back to the earlier concepts - What happens when a YAML file is sent to the K8s SPI Server.
Once the system detects that the YAML file specifies 3 replicas, and the current ReplicaSet does not contain the 3 replicas, the reconciliation loop that is ran by the Deployment Controller will initiate the creation of said replicas. This process, depending on the side of the pods, can take seconds, minutes, or even hours. Once the replicas are online, the control loop will once again validated against the Deployment manager and notice that the number of required replicas matches what is specified in the YAML file. At this point, the cluster is “in balance.”
What happens when a change is made to the YAML file?
Engineers deploy code on a regular basis. Changes are pushed to the applications (new revision), new applications are added (nodes, pods, DaemonSets, etc) and in some cases removed. In Kubernetes, this is done via changes to the YAML file.
Here’s our new YAML file:
Notice that we’ve changed the number of replicas from 3 to 5. You’ll need to issue the following command to apply the changes
At this point, the control loop will notice two things:
- There’s been a change in the Deployment requirements.
- There’s not a matching number of replicas in the cluster to the one specified in the YAML file.
The Deployment controller will run a reconciliation loop that will once again correct the discrepancies between the current state of the cluster and the requirements of the YAML file and deploy 2 replicas.
Kubernetes ReplicaSets and the Deployment Controller
One of the core aspects of Kubernetes is scalability. In other words, the ability to create and delete components based on demand where demand could be a variety of factors. In this case, the API Server will once again process the YAML file and ensure that the changes are adequate, there are no mistakes, etc. Once that’s done, as mentioned above, the deployment manager will coordinate the instantiation of new replicas through the ReplicaSet manager.
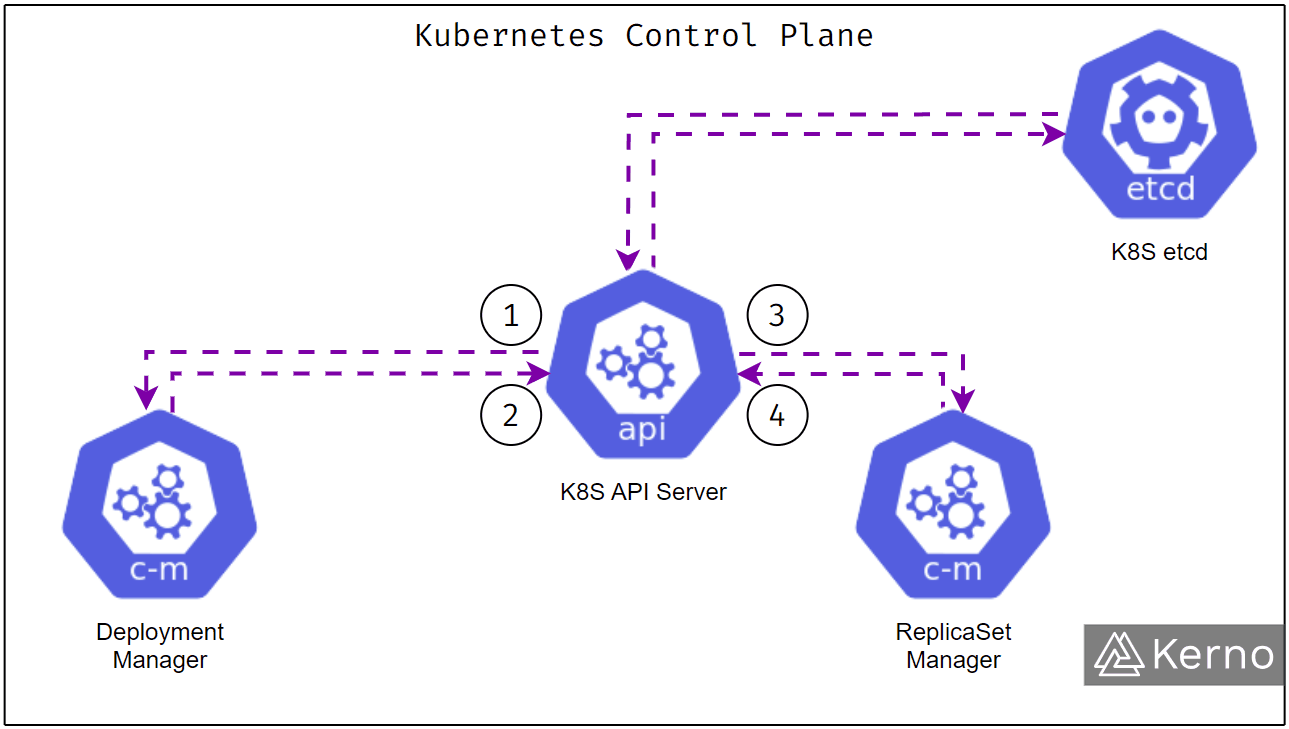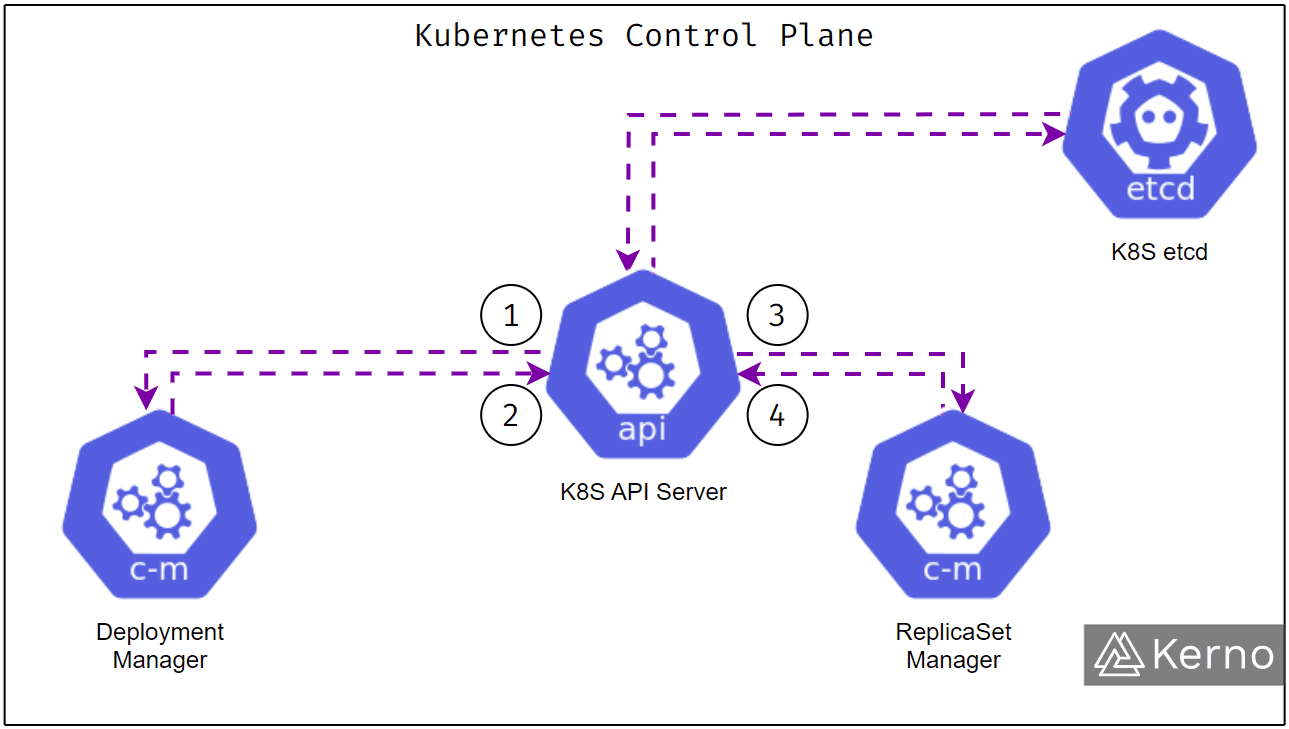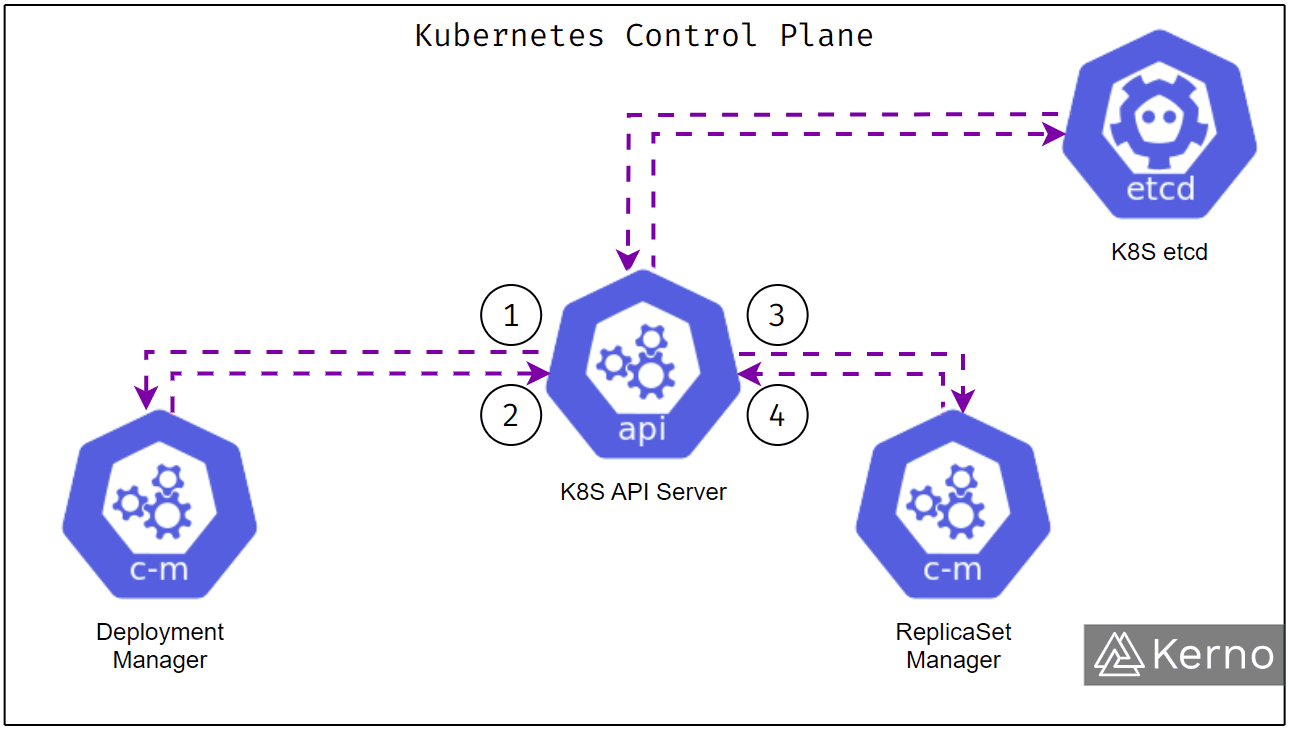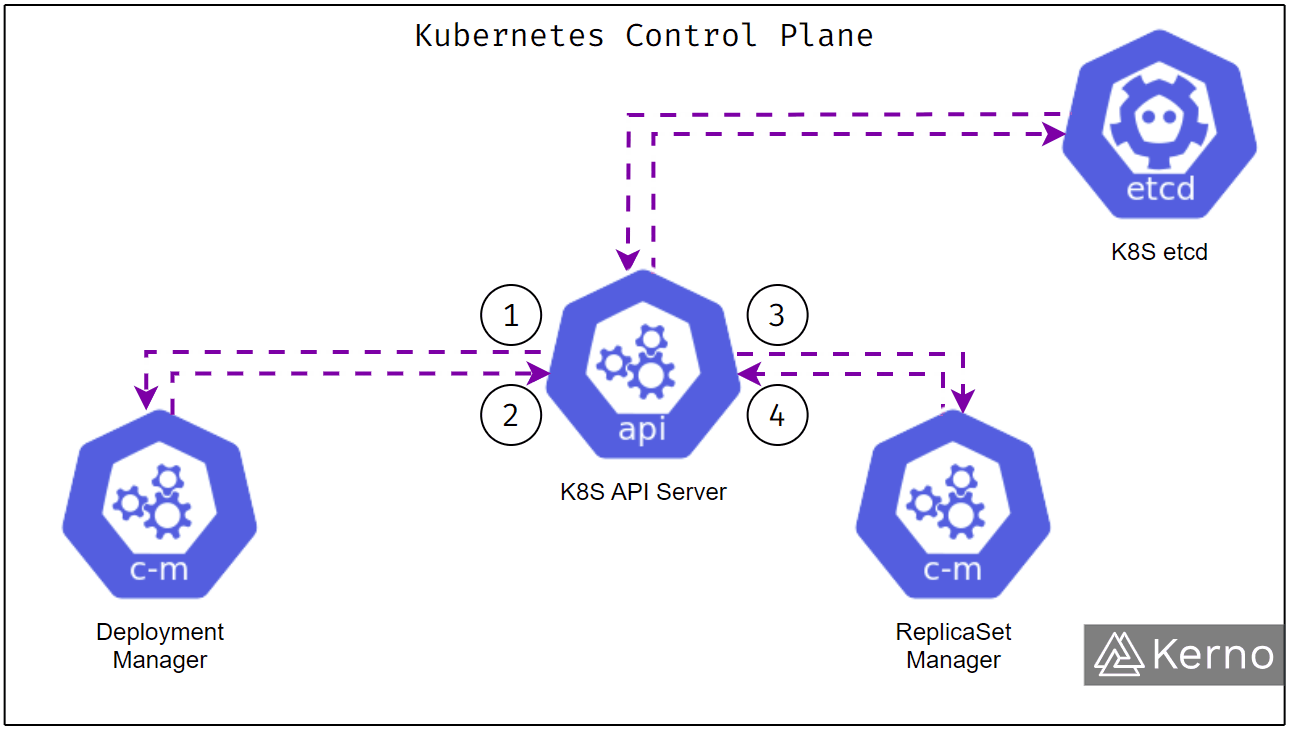
- The API Server will send the deployment YAML file to the Deployment Manager.
- The Deployment Manager will take note of the increased number of replicas and send the information to the API Server.
- The API Server will forward the information to the ReplicaSet Manager.
- The ReplicaSet Manager will manage the deployment of new replicas specified by the YAML file.
Conclusion on Kubernetes Operators
At this point, we have a good understanding of what happens inside of Kubernetes when it comes to Deployments. Where do the operators come in?
The minimum requirements to deploy a Kubernetes ressource are as follows:
- We need a controller that will monitor the state of the cluster and the requirements specified by the Deployment file.
- We need a specification of the deployment, or a YAML file, that will dictate what needs to be deployed within the cluster.
- We need an instance of the Deployment within the Kubernetes etcd controller. This instance is created by the API Server.
Operators will need to create an instance of each one of those components; or the second and third components at a minimum - Custom Resource Definition and Custom Resource. In other words, a Kubernetes Operator isn’t a single element as the documentation may lead you to believe. An operator will allow the user to specify the schema, the deployment, and the control loop. It gives additional control on how the process is executed in the Kubernetes Control Plane.