
Imagine…
We can get a full health check, visibility, and monitoring of our applications without the need to burn developer time, spin up expensive sidecars, or manually instrument a single line of code. Imagine all the time and resources it would save. Or, more importantly, eliminate the friction between people who operate the applications and the people who build the applications.
This is the power of ebpf. It’s the technology equalizer that no one really knows about. In this article, we will dive into ebpf, its use-cases, its limitations and how it will potentially flourish as AI-native development amps up.
What is ebpf?
Imagine eBPF as a Swiss Army knife for the operating system kernel. It's like equipping your kernel with the ability to attach new, specialized tools (written as small programs) that can inspect, monitor, or even influence kernel-level activities without modifying the kernel itself. Much like how browser extensions can add features to a web browser without altering its core code, eBPF programs enhance the kernel's capabilities dynamically and safely.
These programs operate like sensors or filters, listening to data flows (like syscalls and network traffic outlined in figure 1) and providing insights or actions based on predefined logic. Yet, they do this within strict safety confines, ensuring no harm is caused to the system, similar to sandboxing browser scripts. For deeper analysis, check out Karim’s article on ebpf here.

Use Case of ebpf
While eBPF has been around since the 1990s, it has gained prominence in networking and security only in the last decade.
At Netflix, where they process 1 million requests per second, eBPF is used to develop a network observability sidecar that operates with less than 1% CPU overhead. Read more [here].
At Apple, the security engineering team leverages Falco, a tool that provides real-time threat detection for a variety of environments, including individual containers, hosts, Kubernetes, and the cloud. Falco can detect and alert on abnormal behaviors and potential security threats in real-time, such as cryptomining, file exfiltration, privilege escalation in applications, and rootkit installations, among others. Think of Falco as a network security camera that uses syscalls from the kernel to enrich traffic and Kubernetes data. The syscall never lies.
At Kerno, we utilize eBPF capabilities for application networking, enabling us to deliver auto-instrumentation of Kubernetes clusters. This provides end-users with real-time visibility and observability without the overhead of manually configuring SDKs, sidecars, or traffic logs.
eBPF supports a wide range of complex use cases, but many of these require kernel-level engineering expertise. What if you don’t have such expertise but still want to benefit from eBPF? Kerno addresses this challenge with a managed version of eBPF at the application layer called "Preon." Hosted on your cluster, it takes just one Docker command to install. The Kerno team handles all the maintenance while you reap the benefits. This is just one example of a managed eBPF service that offers more than native kernel telemetry.
The Advantages of ebpf
Low Overhead
With eBPF, the collection and aggregation of custom metrics can be performed directly in the kernel, significantly reducing the need for sampling. eBPF can also be tuned to operate with much lower overhead compared to traditional sidecars, agents, and SDKs.
Data Accuracy
The syscall never lies. Telemetry collected at the kernel level is the lowest point in the software stack before hitting bare metal, ensuring users can trust the integrity of this data.
Secure by Default
The eBPF verifier ensures that no program failing to conform to strict standards can be executed. Additionally, eBPF programs must operate within a 60KB memory limit on stack usage, inherently limiting the scope of what they can do and enhancing security. Even if external storage is used like ebpf maps, they all are subjected to constraints.
Equalizes Telemetry Ingestion
eBPF has the potential to transform application-level monitoring and observability. Traditional tools require significant engineering resources for instrumentation and maintenance—work that eBPF can eliminate. Achieving full coverage across clusters with existing tools often costs hundreds of thousands, or even millions, not to mention overage fees. An eBPF-powered approach enables teams to achieve full visibility at a fraction of the cost, delivering the equivalent power of an enterprise observability team in a single program.
Limitations
While bpf trace exists at the network level, it doesn’t provide function level granularity required for distributed tracing. However, the missing component is the traceID, which can be pulled in from your service mesh like istio or OTEL deployments.
Technical Complexity
- While syscalls provide an accurate view, eBPF programs must be carefully designed to ensure they capture the right syscalls at the right granularity. Misconfigurations or blind spots (e.g., missing user-space context) can still affect data completeness.
- Steep Learning Curve: eBPF programming requires knowledge of kernel internals, low-level programming in C, and familiarity with tools like LLVM and eBPF-specific features.
- Limited Debugging Tools: Debugging eBPF programs is challenging because traditional kernel debugging tools are not fully compatible. Developers often rely on tools like bpftool or custom debug output.
- Resource Constraints: eBPF programs run in a restricted environment with limitations on stack size (512 bytes) and complexity (e.g., instruction limits), requiring careful resource management.
Compatibility Issues
- Kernel Version Dependency: eBPF features vary across Linux kernel versions, meaning programs often need to be tailored for specific kernel versions or run on newer kernels.
- Limited Non-Linux Support: eBPF is mainly a Linux-centric technology, with limited support on other platforms, making it less useful in non-Linux environments. AWS is progressing it’s ebpf support for fargate, which will unlock some of the benefits that ebpf brings on serverless monitoring.
In net, the biggest barrier is having deep kernel level expertise.
Ebpf in the AI era
“Data is the new oil” was a popular phrase during the Big Data era, but I believe a more accurate statement today is, “Proprietary data is the new oil.” Most large language models that have fueled the rise of generative AI were trained on openly available data.
In this new era, the ability to mine proprietary data, ingest it, and process it with low computational cost and high accuracy presents a compelling value proposition. With eBBP kernel-to-pod pipelines are achievable.
I can envision a future where eBPF extends beyond its current applications in security, networking, and observability to play a pivotal role in data aggregation and feeding agentic models. As mentioned earlier, syscalls never lie, and technically, there is no limit to the data that can be collected at the kernel level, as long as each program operates within the resource constraints. It fits my model (at least) of the AI-Native building blocks, outlined in figure 3 below.
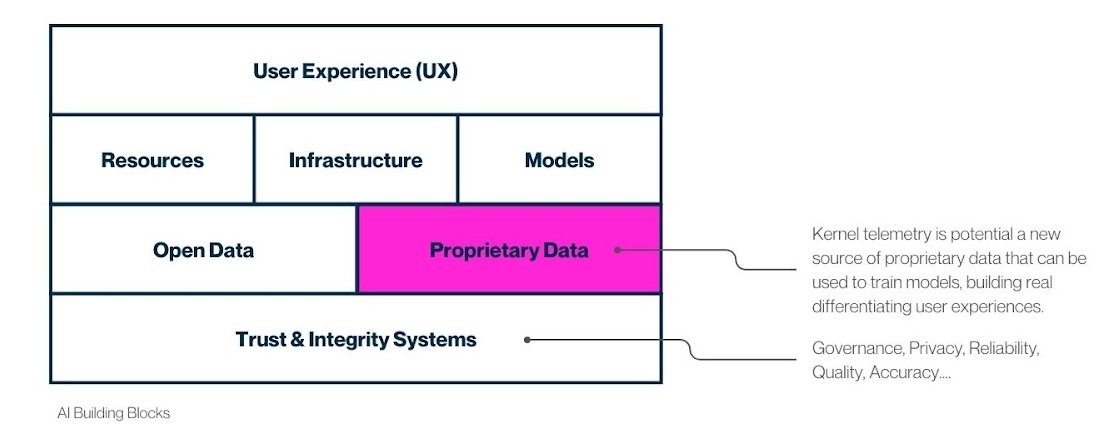
This vision is shared by Thomas Graf, CTO of Isovalent, the company credited with putting eBPF on the map through the release of Cilium and Tetragon. At this year’s eBPF Summit, he shared his perspective on how eBPF can play a pivotal role in the AI era:
- Enabling the GPU/DPU Infrastructure Wave: eBPF’s low-overhead data collection capabilities allow for high-speed, low-computation-cost data collection, making it an essential enabler for GPU and DPU-based systems.
- Bringing Distributed Intelligence to Life: eBPF can revolutionize data collection and retention strategies by enabling smarter, more cost-effective intelligence generation without the high storage and networking costs typically associated with such efforts.
I am equally excited about this potential. For years, our technical focus has been on optimizing databases and data lakes—concepts that, in my opinion, often amount to “let’s keep this data because it might be useful someday.” What truly excites me is the distributed intelligence wave that eBPF could catalyze.
Imagine replacing the inefficient "collect it all" approach or the rigid, uninformed data collection strategies with a dynamic, intelligent system. Such a system would collect only the data needed at a specific moment and automatically adjust ingestion based on identified intelligence gaps. This innovation could massively disrupt the data streaming market, offering all types of customers a more intelligent and efficient way to feed both current models and future agentic models. It could have the same impact as TCP did for internet.. That’s how big and engrained this could be.
There’s still work to do, but data ingestion may have just become intelligent—and, dare I say, sexy.
Conclusion
eBPF is no longer just an obscure technology buried in the depths of the Linux kernel—it’s emerging as a foundational pillar for the next generation of observability, security, and AI-driven data intelligence. By offering low-overhead, real-time telemetry at the kernel level, eBPF eliminates many of the inefficiencies that have plagued traditional monitoring and security solutions. Companies like Netflix, Apple, and Kerno have already harnessed its potential to transform their operations, proving that eBPF is not just theoretical but a production-ready game-changer.
As AI-native applications continue to grow, eBPF’s role in data aggregation and distributed intelligence will only become more critical. The ability to capture accurate, real-time data at the kernel level—without massive computational overhead—opens doors for more efficient AI pipelines, intelligent ingestion strategies, and a future where data collection is dynamic rather than wasteful. In this new paradigm, eBPF is not just a networking or security tool—it’s a key enabler of the next wave of technological evolution.
The world of technology is full of well-kept secrets, but eBPF won’t stay hidden for long. It has the potential to redefine how we interact with data, power AI-native infrastructures, and eliminate decades-old inefficiencies in observability. The only question left is: how soon will the rest of the industry wake up to its potential?