
YAML Syntax
YAML stands for YAML Ain’t Markup Language and is typically specified within two files extensions - .yml and .yaml. Both of them are accepted and are identical in functionality.
YAML Indentation
Like the Python programming language, YAML is structured via indentations in the file. This practice reduces the amount of code but requires the end-users to be extra careful about those spaces and tabs. Let’s take a look at a basic example:
In the code snippet above, notice that we’ve declared two objects with no indentation on the left side - “myApplication1” and “myFactory.” Each object has an array - the “myApplication1” object has an array called “robot”, while the “myFactory” object has an array called “assemblyLine.” Both of these objects are indented to the second level using 2 spaces or a single tab. Lastly, in the same example, we notice a set of key-value pairs associated with each array. Each key-value pair has four spaces or two tabs in front of it.
As you can see, indentation is critical in specifying YAML files. If you’re unsure about your file, there’s a solution! - You can check it using one of the many validators available online. We’ll list a few options below.
YAML Key Value Pairs
Key Value pairs are a fundamental concept in a variety of programming languages. In YAML, you can specify key-value pairs as one would expect - [key]: [value]. Let’s take a look at an example:
In the code snippet above, you’ll notice that we’ve specified four key-value pairs - two are assigned a string, one an integer, and the last one a floating-point value. We’ll cover the data types supported in YAML below, but this example should give you an idea of how to create basic key-value pairs.
YAML Mapping
YAML Mapping is essentially a dictionary in programming languages. In other words, a map is an unordered list of key value pairs in which the only restriction is that every key is unique. Here are two examples of YAML maps:
As you can see in the examples above, it’s possible to store key value pairs of different types inside of the same YAML map. You’ll find a complete list of supported data types in a section below.
YAML Sequences
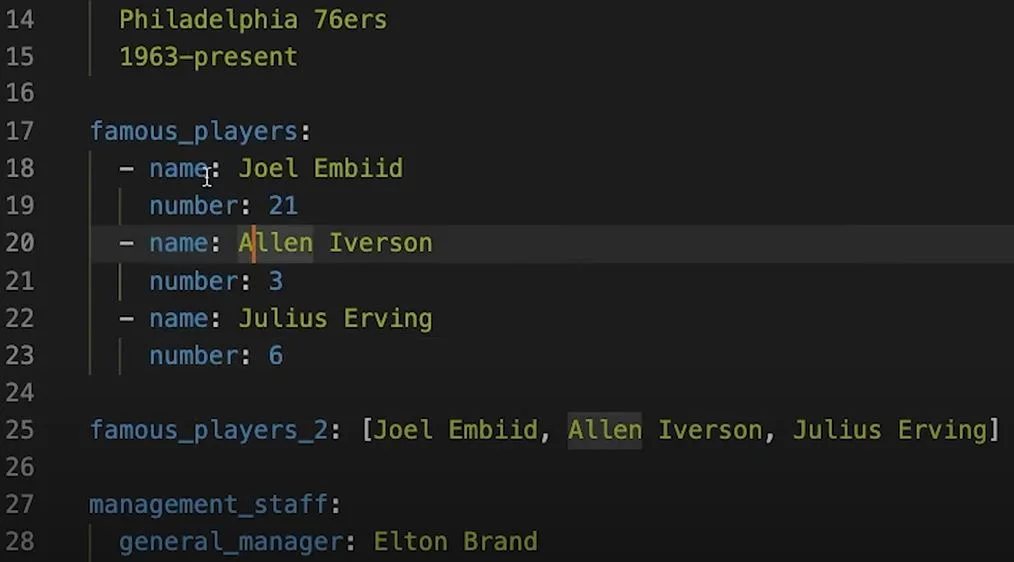
YAML sequences can be instantiated by using a hyphen in front of the name. They’re essentially lists from programming languages. Here are some examples:
Sequences are very versatile in YAML. As the examples above demonstrate, you can create a list of objects, a list of key-value pairs, or a nested list.
YAML Comments
Comments play an important role in every software development language, document, etc. In YAML, the user can specify comments by using the # symbol; everything will be ignored after it. Here are some example:
YAML Data Types
YAML supports a variety of basic data types - strings, integers, floating point, and booleans.
YAML Data Types - Integers
Integers can be defined as decimal, octal, or hexadecimal in YAML. Let’s take a look at a few examples:
Notice that the octal value is specified via a leading “0” while the hexadecimal value is led by “0x.”
YAML Data Types - Floating-Point
Floating Point values can be defined as fixed or exponential in YAML. Let’s take a look at a few examples:
It’s important to note that you’ll need to create error checks when using typed languages to ensure that the values are read properly from YAML files.
YAML Data Types - Boolean
Boolean values can be defined via three keywords in YAML - True / False, Yes / No, and On / Off. Let’s take a look at a few examples:
YAML Data Types - Strings
Strings are Unicode in YAML. Let’s take a look at a few examples:
YAML Data Types - Folding Strings
It’s possible to write long strings in YAML by using the “>” operator. These strings will be concatenated into a single string when read from the file. In other words, it’s just a graphical representation of a single string. Let’s take a look at an example:
YAML Data Types - Block Strings
It’s possible to write multi-line strings in YAML by using the “|” operator. Let’s take a look at an example:
Complete YAML File Example - Kubernetes Deployment
Kubernetes Deployments are specified using YAML. In this section, we’re going to walk through an example of a deployment file and dissect how it’s structured to accomplish the task of deploying the correct Kubernetes assets.
Line 1 - apiVersion: apps/v1
The key-value pair specifies the version of application this file will be referencing. When crafting Kubernetes resource manifests, a crucial initial step involves specifying the apiVersion for the resource. While you might accurately "guess" for common resources, mastering the ability to determine it within your cluster is a valuable skill. The apiVersion follows the format api_group/version.
Every object definition in Kubernetes necessitates an apiVersion field. With each Kubernetes release that enhances the available features or modifies its API, a new apiVersion is established.
Line 2 - kind: Deployment
Kubernetes allows for a variety of different services to be deployed via the YAML file. In this case, we’re using a key-value pair to specify that this file represents a Deployment type.
Line 3, 4 - metadata: name: nginx-deployment
Notice that this is a map that contains a single key-value pair. In this case, we’re going to associate the name of “nginx-deployment” with the ReplicaSets and Pods that will be created as a part of the deployment specified further in this YAML file.
Line 5, 6, 7, 8 - spec: selector: matchLabels: app: nginx
Labels serve as key/value pairs attached to objects like Pods in Kubernetes. Their purpose is to specify meaningful and relevant identifying attributes for users without directly implying semantics to the core system. Labels are instrumental for organizing and selecting subsets of objects. They can be assigned to objects during creation and subsequently added or modified at any time. Each object can possess a unique set of key/value labels, where each key must be distinct for a given object.
Line 9 - replicas: 2 # tells deployment to run 2 pods matching the template
You’ll notice the key-value pair on line 9 as the only one with a comment on that line. YAML allows users to specify in-line comments by using the # character. Anything after said character won’t be executed just like any other comment in a programming language. In this example, we’re asking the K8S engine to create 2 replicas at the moment our deployment is executed.
Line 10, 11, 12, 13 - template: metadata: labels: app: nginx
In this case, we’re applying the label at the pod label unlike the like 5 above where we’ve applied it at the ReplicaSet level.
Line 14, 15, 16, 17 - spec: containers: - name: nginx image: nginx:1.14.2
We’re using both a map and a sequence in this specification of the image we’re going to deploy onto the pod.
Line 18, 19 - ports: - containerPort: 80
We’re using a list to specify the ports on which our container will be listening on. 80 is the standard HTPP post.
Kubernetes Deployment Conclusion
The example above illustrates a basic Kubernetes Deployment file that contains the specification of two ReplicaSets of pods that run a service called nginx. By understanding the structure and syntax of YAML, we’re able to quickly read through the document and understand what’s going on. Remember that the Kubernetes documentation will call out how these parameters need to be specified in order to deploy the services properly.
YAML vs JSON vs XML
You’ll find one of the three formats, YAML, JSON, or XML in a variety of applications. In general, you’ll see JSON in data protocols and data processing, YAML in definition or specification sheets, and XML in a mix of the two. Having a general understanding of all three is beneficial if you’re working in software development - if you’re familiar with one of them, the difference with the others is the syntax. Let’s take a look at an example of JSON and XML since we’ve seen plenty of examples of YAML above:
JSON Example
JSON is commonly used in a communication called MQTT. If you’re interested in the protocol, there’s an entire website dedicated to it here - MQTT: The Standard for IoT Messaging. Here’s a simple JSON format that represents the payload of an MQTT message. It’s common to create these formats and parse the messages in software according to the format:
Notice that JSON is formatted by using objects - The example above has two objects: foo_data and my_payload. Each object contains a string and an integer / timestamp.
XML Example
XML is a markup language that is used in a variety of applications - data structures, documentation, web apps, and more. Here’s an example of a data structure that is used to specify two distinct production plants.
You’ll immediately notice from the example above that XML is much more explicit than YAML and JSON. However, it accomplishes a similar purpose - you can declare objects and nest them to outline a hierarchy.
Data Type Support
It’s important to note and know that JSON, XML, and YAML support different data types. XML supports complex data types - images, charts, tables, etc. JSON, on the other hand, was designed to specify data structures and thus only supports booleans, numbers, strings, arrays, and objects. YAML contains a mix of the two as we discussed in an earlier section.
Conclusion on how is the yaml data format structure different from JSON and XML?
In general, you’ll see YAML used for configuration; while JSON is most often found in data structures that are passed to and from APIs. Lastly, XML is going to be often seen in situations where data needs to be passed directly between two applications.
Conclusion on YAML
YAML stands for YAML Ain’t Markup Language and is commonly used to specify a variety of settings for different applications. YAML files can use the .yaml or the .yml extension interchangeably. YAML is commonly used to specify Kubernetes deployments. YAML provides a variety of structures and syntax to accommodate fairly sophisticated data structures. If you'e curious about an actual use case of YAML for Linux IP address configuration, we've written a separate tutorial on the topic!